AI 모델 성능 향상의 첫걸음: 데이터의 재발견
인공지능 모델의 성능은 곧 데이터의 품질과 양에 달려있다고 해도 과언이 아닙니다. 모델 학습에 사용되는 데이터는 마치 요리의 식재료와 같습니다. 신선하고 질 좋은 재료가 맛있는 요리를 만들듯, 깨끗하고 편향되지 않은 데이터는 AI 모델의 정확도와 신뢰성을 크게 좌우합니다. 따라서 모델 성능을 향상시키기 위한 첫 번째 단계는 바로 데이터 정제와 전처리입니다. 결측치 제거, 이상치 탐지 및 처리, 데이터 형식 통일, 그리고 필요에 따라서는 데이터 증강(augmentation) 기법을 적용하여 모델이 학습할 수 있는 최적의 데이터셋을 구축하는 것이 중요합니다. 실제 사례로, 자율주행차 AI 모델의 경우 날씨, 시간대, 도로 상황 등 다양한 변수를 반영한 데이터를 충분히 확보하고 이를 정교하게 가공함으로써 예측 정확도를 획기적으로 높일 수 있었습니다. 출처: AI 연구 논문 및 기술 보고서 종합 분석

모델 아키텍처 최적화: 더 똑똑한 AI를 위한 설계
AI 모델의 성능은 그 기반이 되는 아키텍처 설계에 따라 크게 달라집니다. 마치 건물의 뼈대가 튼튼해야 고층 빌딩을 지을 수 있듯이, 모델의 신경망 구조는 학습 능력과 추론 속도를 결정하는 핵심 요소입니다. 최신 연구 동향을 반영한 효율적인 아키텍처를 선택하거나, 기존 모델을 특정 문제에 맞게 수정하는 작업이 필요합니다. 예를 들어, 이미지 인식 분야에서는 컨볼루션 신경망(CNN)의 깊이나 레이어 구조를 조절하고, 자연어 처리 분야에서는 트랜스포머(Transformer) 모델의 어텐션 메커니즘을 개선하는 방식 등이 성능 향상으로 이어집니다. 모델 아키텍처의 복잡성과 성능 간의 균형을 찾는 것이 중요합니다.

학습 전략의 정교화: 똑똑하게 배우는 AI
모델을 학습시키는 과정, 즉 학습 전략 또한 성능 향상에 지대한 영향을 미칩니다. 단순히 많은 데이터를 반복해서 학습시키는 것만이 능사는 아닙니다. 어떤 최적화 알고리즘을 사용할지, 학습률(learning rate)은 어떻게 조절할지, 정규화(regularization) 기법을 적용하여 과적합(overfitting)을 방지할지 등 세밀한 조정이 필요합니다. 또한, 사전 학습된(pre-trained) 모델을 활용하여 전이 학습(transfer learning)을 시도하는 것도 효율적인 성능 향상 방법 중 하나입니다. 이는 마치 이미 많은 지식을 쌓은 전문가에게 특정 분야의 추가 교육을 시키는 것과 같습니다. 효과적인 학습 전략은 모델이 더욱 빠르고 정확하게 목표를 달성하도록 돕습니다.

하이퍼파라미터 튜닝: 성능의 미세 조정
모델의 학습률, 배치 크기(batch size), 드롭아웃 비율(dropout rate) 등 직접적으로 학습 과정에 영향을 미치는 값들을 '하이퍼파라미터'라고 합니다. 이러한 하이퍼파라미터들을 최적의 조합으로 찾아내는 과정을 '하이퍼파라미터 튜닝'이라고 합니다. 이는 마치 악기의 음정을 미세하게 조절하여 최고의 소리를 만들어내는 과정과 같습니다. 그리드 탐색(Grid Search), 랜덤 탐색(Random Search), 베이지안 최적화(Bayesian Optimization) 등 다양한 튜닝 기법이 존재하며, 적절한 하이퍼파라미터 설정은 모델 성능을 수치적으로 크게 향상시킬 수 있습니다.
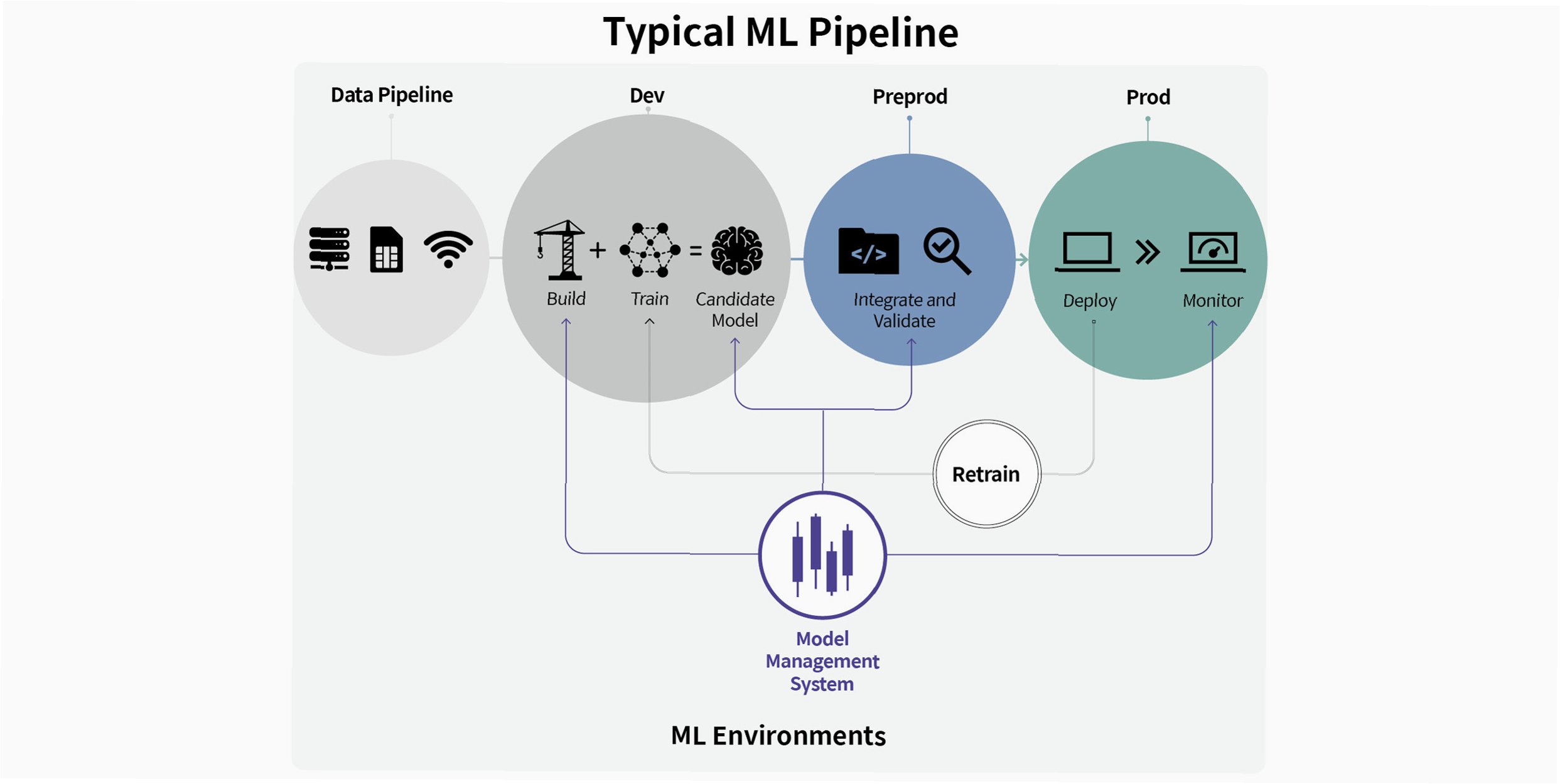
평가 및 개선: 끊임없이 진화하는 AI
모델이 학습되고 튜닝되었다면, 이제 성능을 객관적으로 평가할 차례입니다. 정확도(accuracy), 정밀도(precision), 재현율(recall), F1 점수 등 다양한 평가 지표를 사용하여 모델이 실제 환경에서 얼마나 잘 작동하는지 검증해야 합니다. 만약 평가 결과가 기대에 미치지 못한다면, 다시 이전 단계로 돌아가 데이터, 아키텍처, 학습 전략, 하이퍼파라미터 등을 재검토하고 개선하는 반복적인 과정을 거쳐야 합니다. 이러한 지속적인 평가와 개선의 순환이야말로 AI 모델이 시간이 지나도 뒤처지지 않고 최상의 성능을 유지하는 비결입니다.

AI 모델 성능, 이렇게 끌어올리세요!
AI 모델의 성능 향상은 데이터 정제부터 아키텍처 최적화, 학습 전략 정교화, 하이퍼파라미터 튜닝, 그리고 지속적인 평가와 개선이라는 체계적인 절차를 통해 이루어집니다. 각 단계는 유기적으로 연결되어 있으며, 이 모든 과정을 꼼꼼하게 수행해야만 AI 모델의 잠재력을 최대한 끌어낼 수 있습니다.
'궁금해하실 만한 점들'
Q.데이터 증강이란 무엇인가요?
A.데이터 증강은 기존 데이터를 변형하거나 조합하여 학습 데이터의 양을 늘리는 기법입니다. 이미지의 경우 회전, 확대, 색상 변경 등을, 텍스트의 경우 동의어 대체, 문장 재구성 등을 통해 더 다양한 데이터를 만들어 모델의 일반화 성능을 높입니다.
Q.과적합(Overfitting)이란 무엇이며 어떻게 방지하나요?
A.과적합은 모델이 학습 데이터에 너무 맞춰져서 새로운 데이터에 대한 성능이 떨어지는 현상입니다. 이를 방지하기 위해 정규화 기법(L1, L2), 드롭아웃, 조기 종료(early stopping) 등의 방법을 사용합니다.
Q.전이 학습(Transfer Learning)은 왜 효과적인가요?
A.전이 학습은 대규모 데이터셋으로 미리 학습된 모델의 지식을 가져와 새로운 작업에 적용하는 방식입니다. 이를 통해 적은 데이터로도 높은 성능을 얻을 수 있으며, 학습 시간도 단축할 수 있습니다.

'IT 인터넷' 카테고리의 다른 글
| 콘텐츠 IP, 무한한 가능성의 세계를 열어줄 당신의 보물 지도 (0) | 2026.01.23 |
|---|---|
| 인종차별 논란 딛고 '진심 사과' 션 오말리, UFC 324 밴텀급 판도 뒤흔들까? (0) | 2026.01.23 |
| AI 데이터센터, 성공적인 구축을 위한 실전 노하우 대공개 (0) | 2026.01.23 |
| 변화의 바람을 타고, 성공적인 조직 개편으로 도약하는 비밀 노하우 (0) | 2026.01.23 |
| 154km 대만 국대 투수, KBO 넘어 MLB 꿈꾼다! 한화의 베스트 시나리오 공개 (0) | 2026.01.23 |